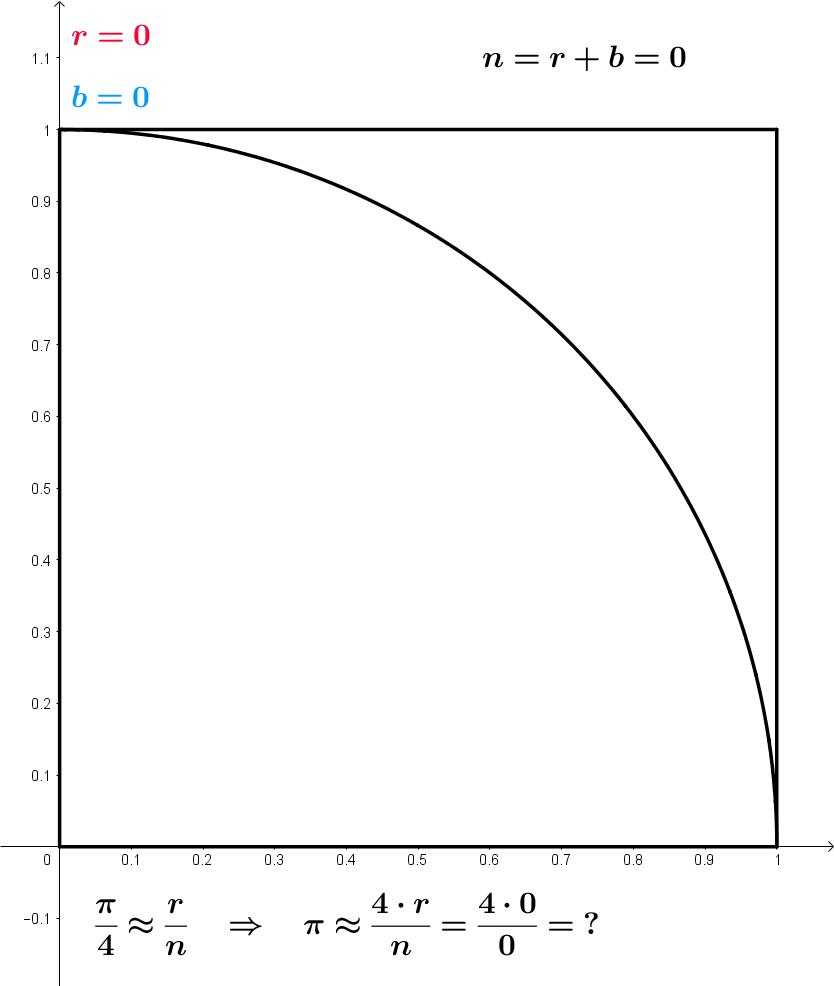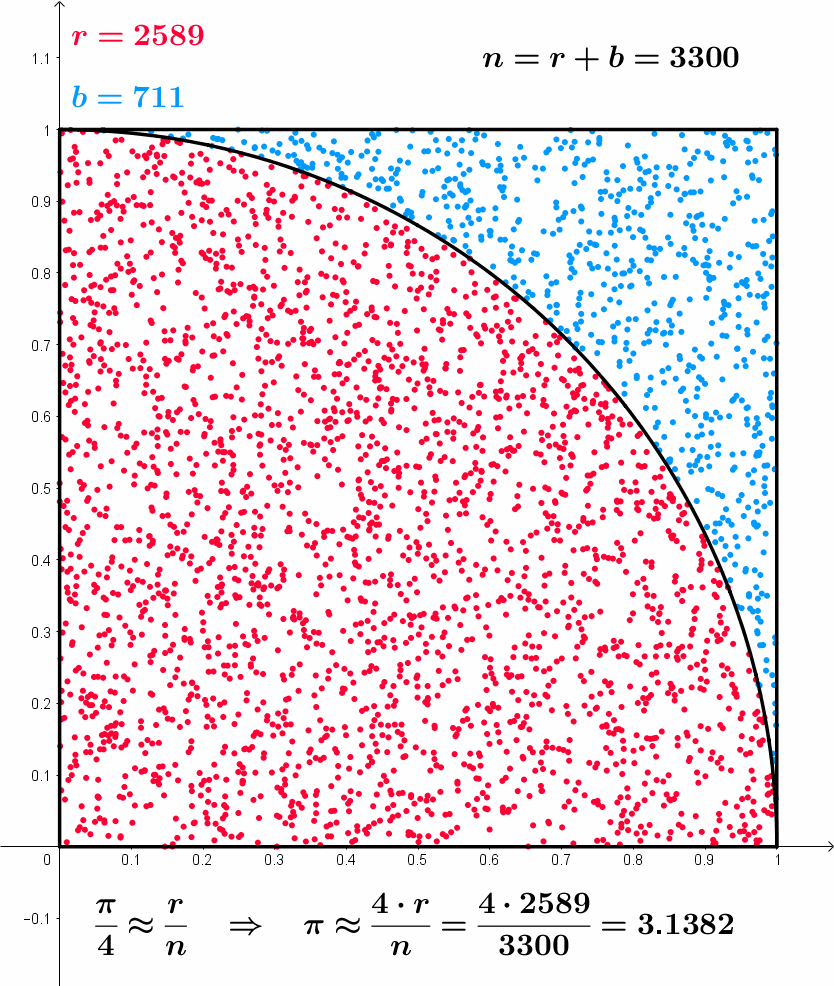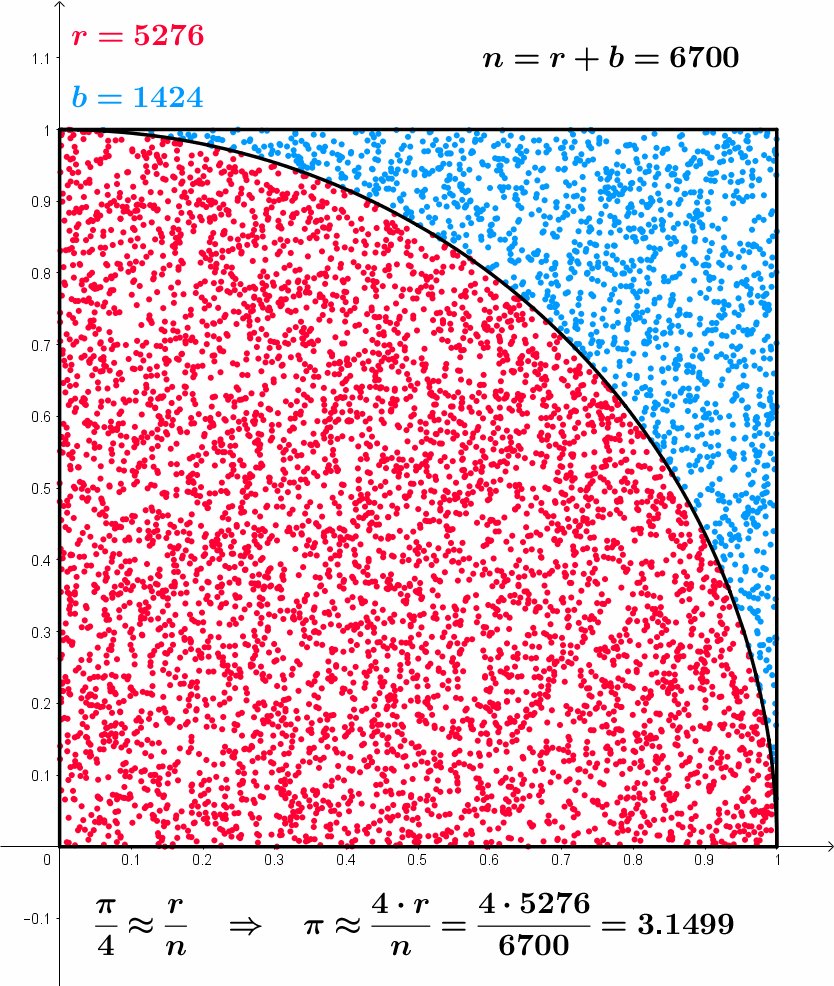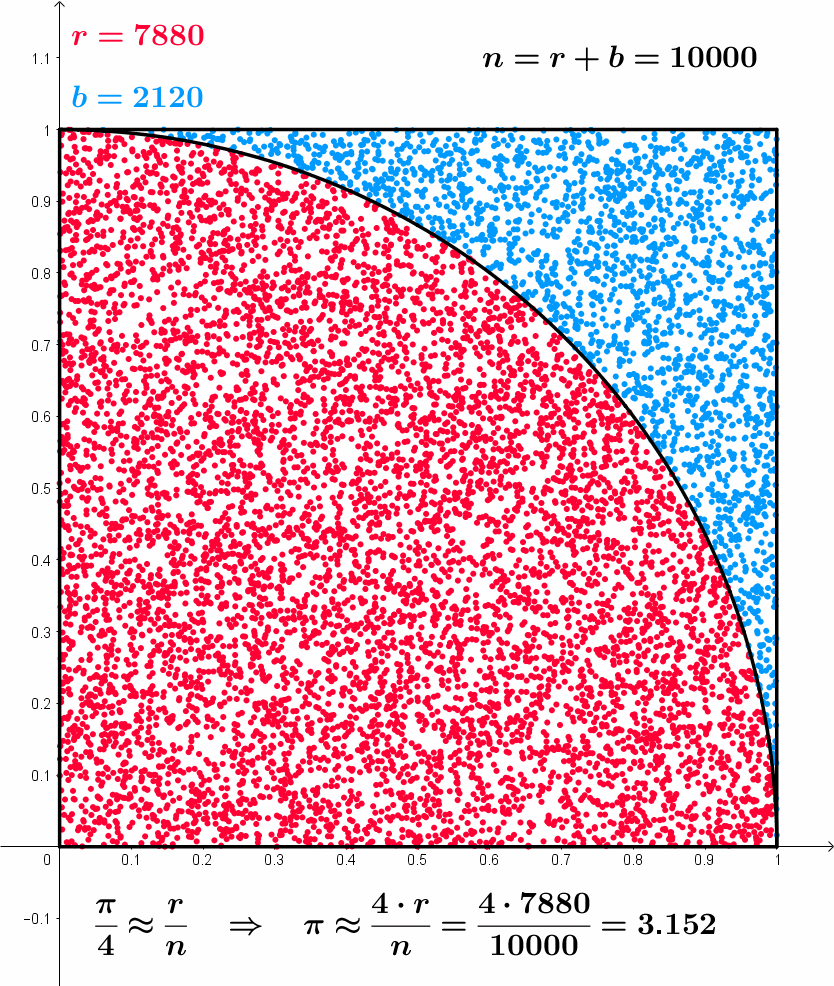
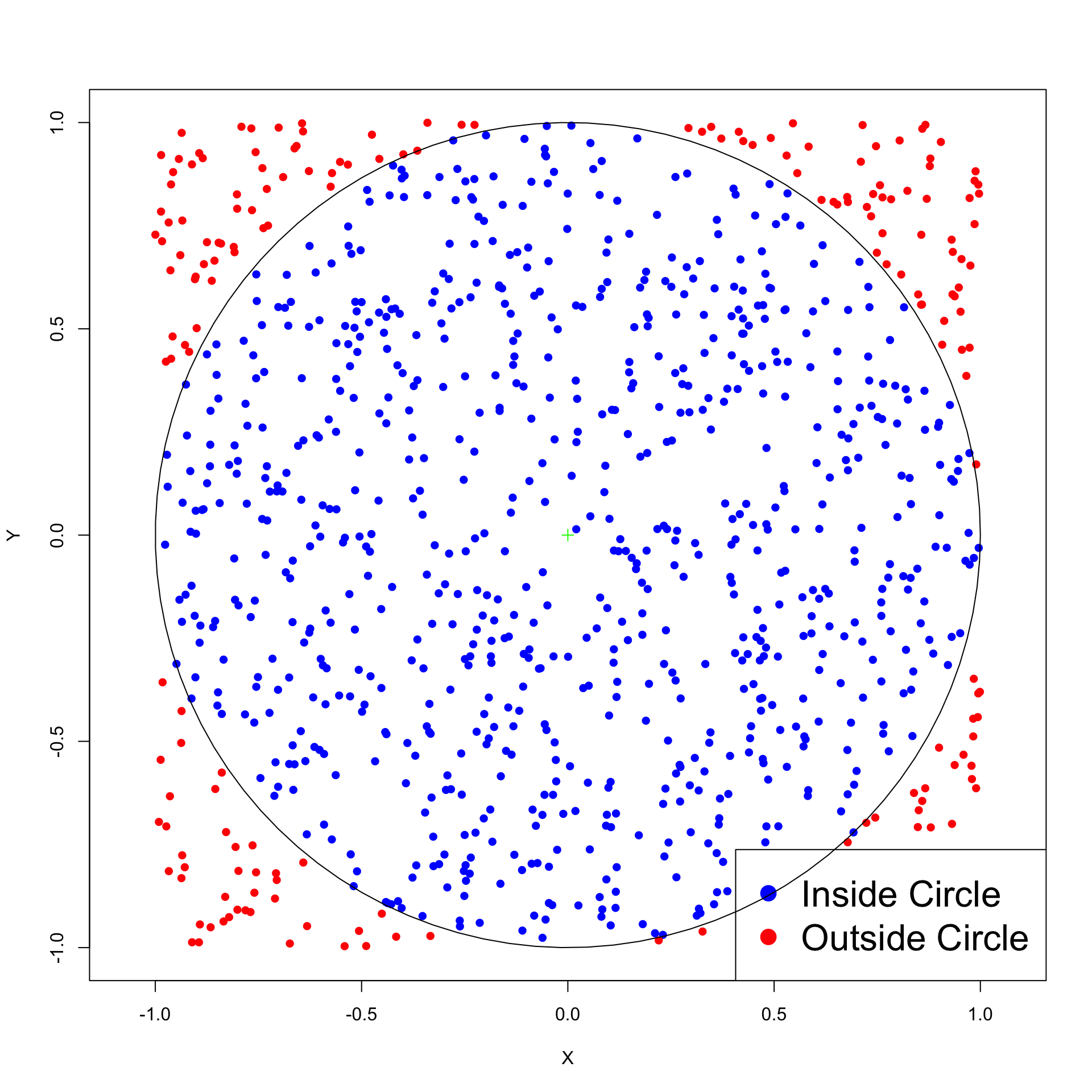
After 10000 iterations pi is 3.14200000, error is 0.00040735
After 20000 iterations pi is 3.14100000, error is 0.00059265
After 30000 iterations pi is 3.14573333, error is 0.00414068
After 40000 iterations pi is 3.14170000, error is 0.00010735
After 50000 iterations pi is 3.14736000, error is 0.00576735
After 60000 iterations pi is 3.14866667, error is 0.00707401
After 70000 iterations pi is 3.14628571, error is 0.00469306
After 80000 iterations pi is 3.14470000, error is 0.00310735
After 90000 iterations pi is 3.14613333, error is 0.00454068
After 100000 iterations pi is 3.14672000, error is 0.00512735
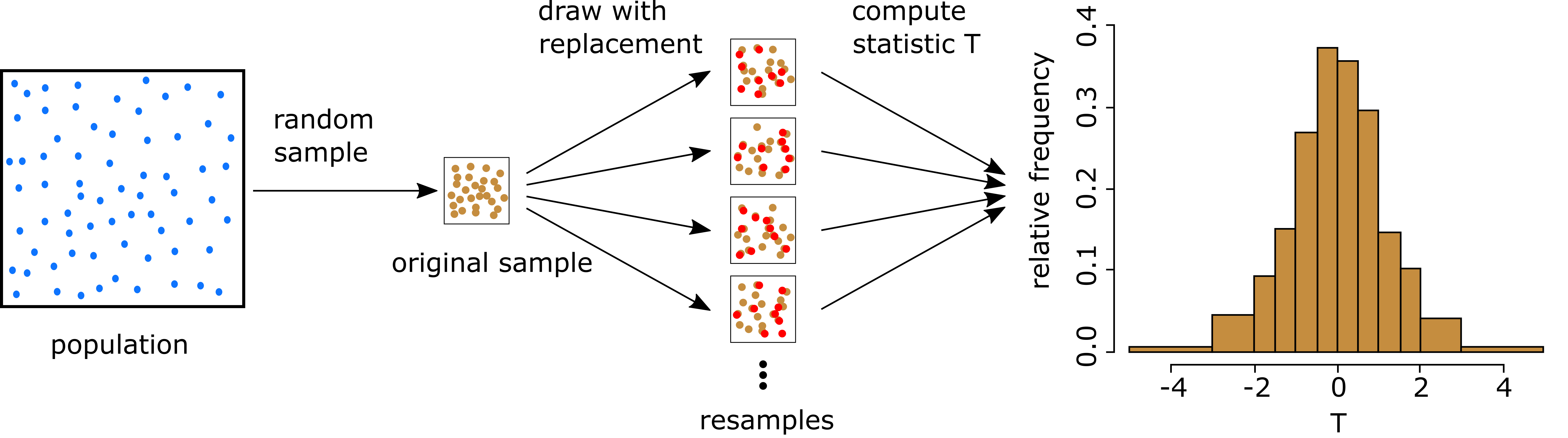
Main Bootstrap idea
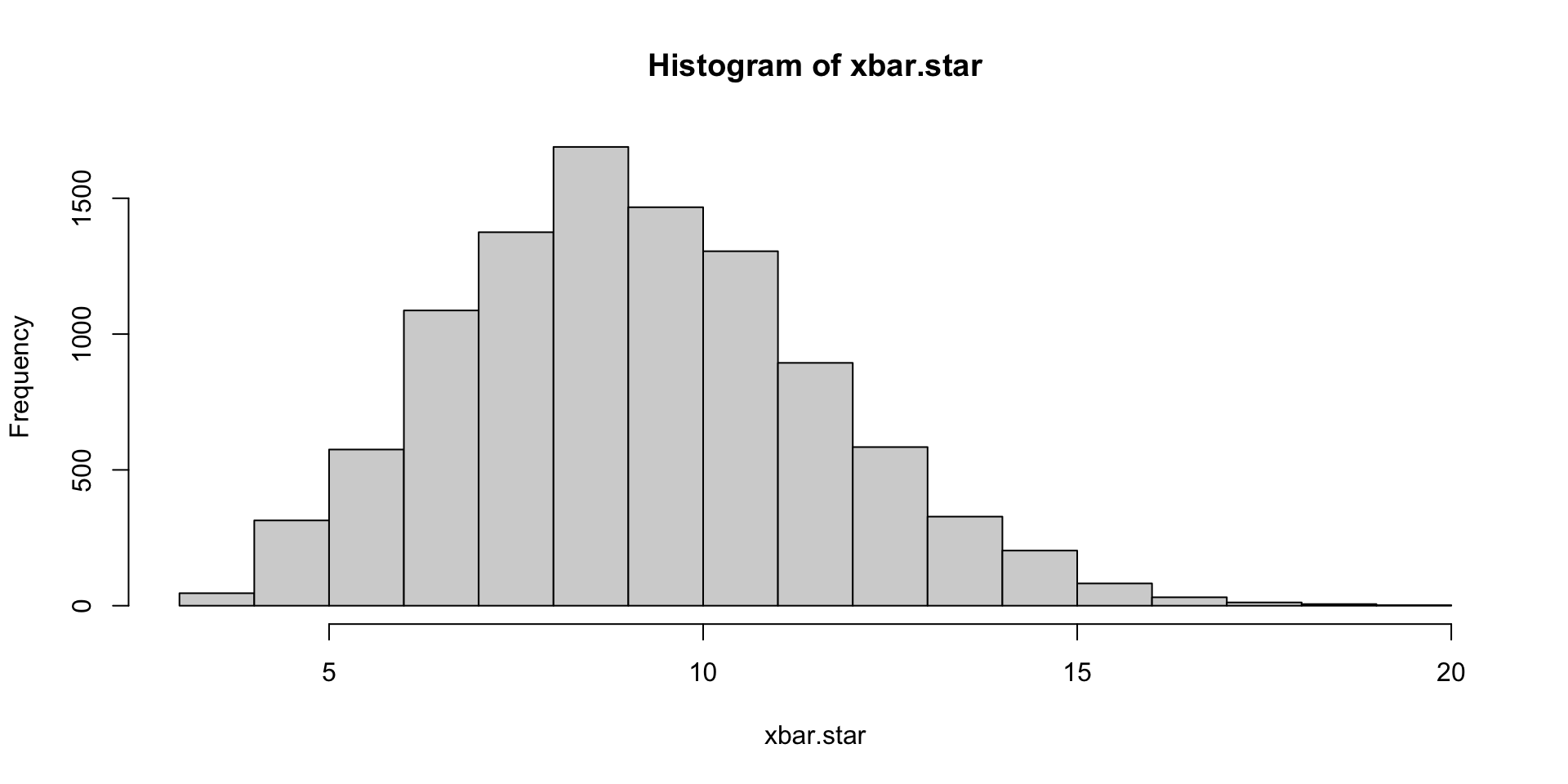
Setting: Assume given the original sample x_1,\ldots,x_n from unknown population f
Bootstrap: Regard the sample as the whole population
Replace the unknown distribution f with the sample distribution \hat{f}(x) = \begin{cases} \frac1n & \quad \text{ if } \, x \in \{x_1, \ldots, x_n\} \\ 0 & \quad \text{ otherwise } \end{cases}
Any sampling will be done from \hat{f} \qquad \quad (motivated by Glivenko-Cantelli Thm)
Note: \hat{f} puts mass \frac1n at each sample point
Drawing an observation from \hat f is equivalent to drawing one point at random from the original sample \{x_1,\ldots,x_n\}
{kind=link}
#/media/File:Illustration_bootstrap.svg){kind=link}